
Data Download and Initial Neural Network Training Results
I downloaded and cleaned all of the files from Mighty Optical Illusions and ViperLib into JPEG (.jpg) images. They are available for download from https://www.floydhub.com/robertmax/datasets/illusions-jpg and the source files and build process can be found on https://github.com/robertmaxwilliams/optical-illusion-dataset.
A greatly reduced version of around 500 images can be found in this floydhub dataset. Training a GAN on these might yield better results than the last attempt with the full dataset (see below).
Classifier
I trained the “bottleneck” of an image classification model, taken from the tensorflow models repo, on the moillusion images. I used a smaller subset of the categories, categories that had at least 20 images and seemed relevant to the goals of the project.
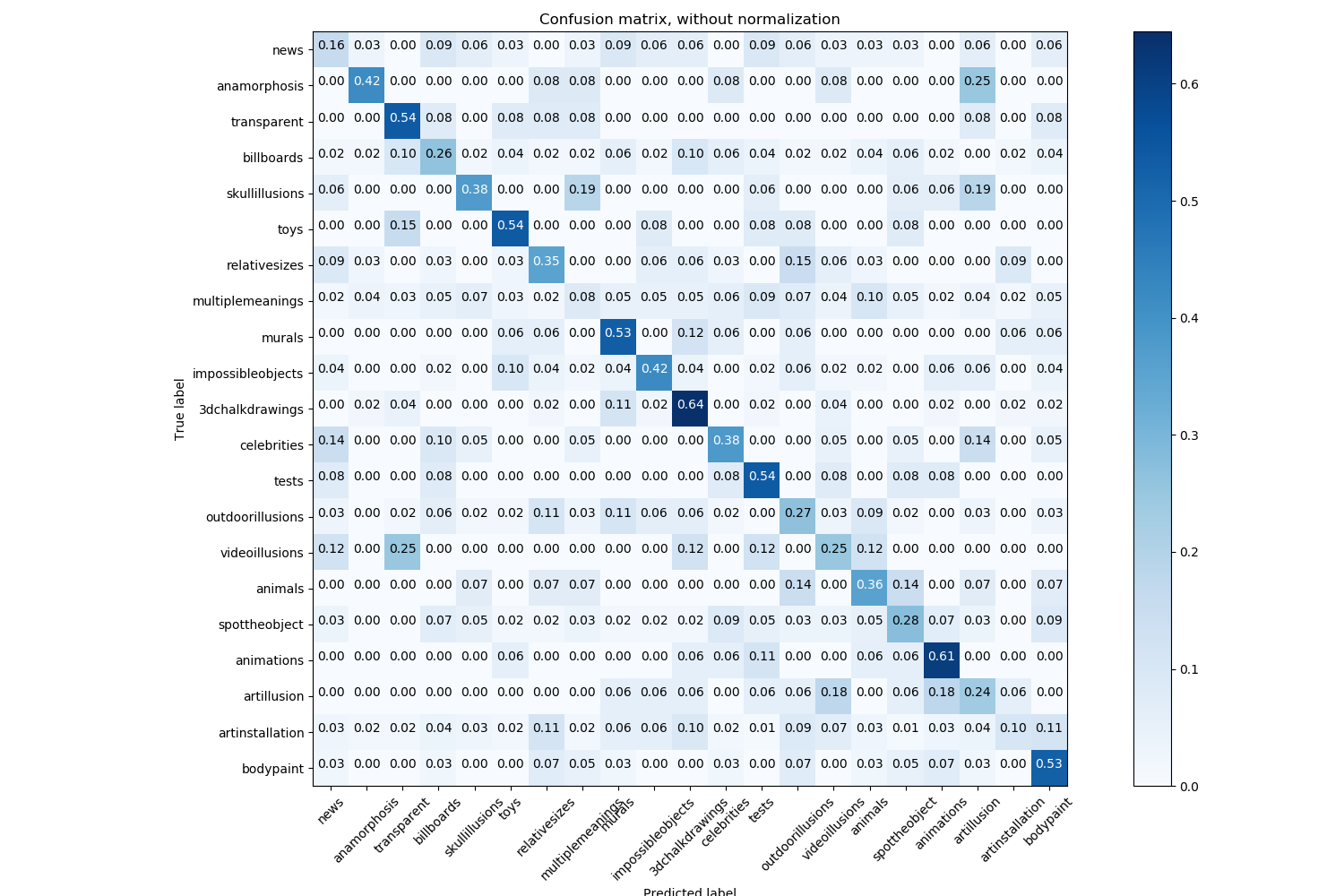
It performed much better than random, but not very well. I doubt it learned anything meaningful to the data, only texture and context clues that roughly correlate with the assigned classes. As well, the data is multi-class but I treated it as single class by including an images in all of its given classes. This means that on a multiclass image, it was guessing the class. I didn’t account for this in the results, which I really should have.
I need to repeat this study with a proper multiclass model. I want to make it from scratch in Keras or Tensorflow, but will need more computing power to train the full image convolution layers instead of just the dense bottleneck layers which I trained on my laptop.
GAN Failure
This is the second time I’ve attempted to train a GAN. The first was on kickstarter images, and led to some strange shapes and textures, but nothing sellable. This time I used the full dataset linked above, and got similar results. It learns… something. It’s hard to say what exactly. One thing I realized in hindsight is that later in training, every image in the group looks exactly the same. A lack of variety within a batch indicates some sort of mistake on my part setting the model parameters, not just with the data.


 training progression of the hyperGAN model on the viperlib images_
training progression of the hyperGAN model on the viperlib images_
I only attempted one full training run, and let it go overnight until I used up all of my floydhub credits. Dr. Yampolskiy suggested that I could use the university’s computing resources, which would make it practical to experiment more with these computationally expensive models. With more experimentation and a more narrow dataset, I might actually get a model to generate images that create an illusion, instead of the illusion-of-being-colorful-blobs that GAN models are so eager to produce.
What’s Next
I’m working over the summer on a machine learning project (details soon) and should be able to apply my new skills to this project. So far I’ve spent most of my time working with the data, and very little tweaking the actual models. Now that I have a nice clean dataset and two baseline projects, I can improve upon it from here. The data work isn’t totally done; the disparity between viperlib and moillusions is a difficult problem that needs to be resolved thoughfully. A full human labeling of the dataset would be nice, but I would need to recruit help to make high quality labeling feasible, and make software to streamline the process.